

A Different Perspective on The ExO Attributes
What if we conceive the SCALE attributes as our organizational sensors because we want them to detect something we want them to detect? And the IDEAS attributes are ‘layers’ in organizations that help us make sense of what we are sensing.
The eleven ExO attributes are at the core of exponential transformation and laid out=in the book Exponential Organizations. As we speak, this book is in the process of a significant upgrade from version 1.0 to 2.0. Participating in the discussions with a small group of ExO coaches and Salim Ismail, we conclude that the attributes are way richer than conceptualized originally. Each session led to new insights, making the attributes more profound. Probably we are leapfrogging to ExO attributes 3.0. Indeed, seeking alignment with Web 3.0 is a logical pathway of how organizations can adapt to that level of using an attribute.
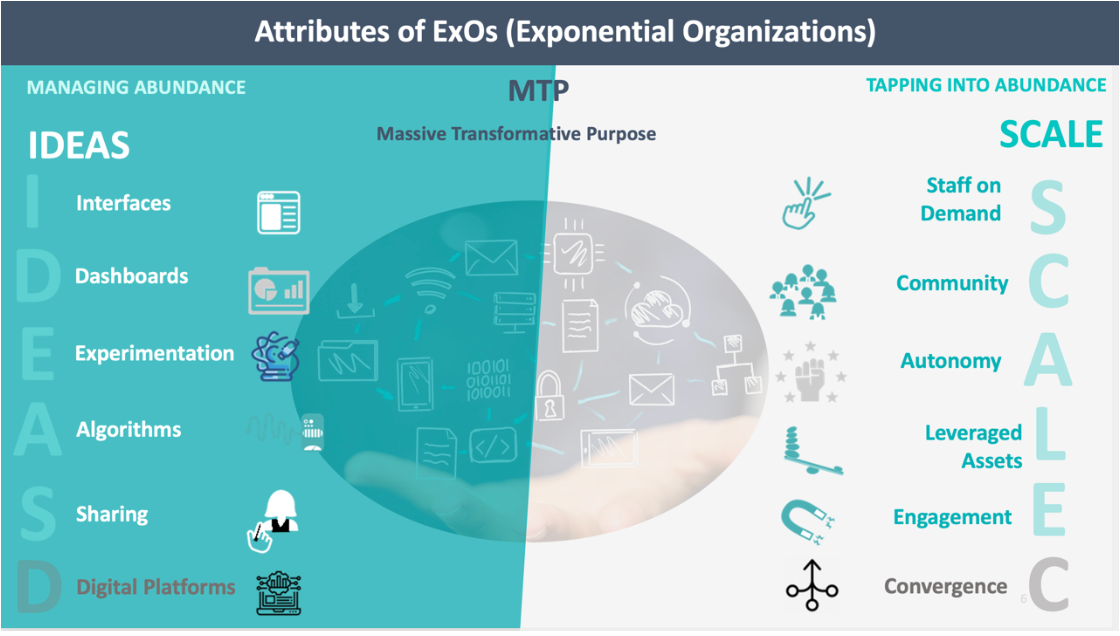
In many visualizations, the ExO attributes have been portrayed as a brain. In the right part of the brain, the SCALE attributes reside, whereas the IDEAS reside in the left part. It suggests that the left is the logic, the rational part, and the right is the creative function. Well, let me be clear right from the beginning, this distinction doesn’t hold anymore. If we are in a creative process, fMRI shows active parts all over our entire brain. This also counts for rational processes. But for another reason, the analogy is interesting for a different view that I’m going to use.
What if we conceive the SCALE attributes as our organizational sensors because we want them to detect something we want them to detect? And the IDEAS attributes are ‘layers’ in organizations that help us make sense of what we are sensing. However, we will notice that some attributes may not be rightly positioned. Oops! No worries, this can be solved due to the brain's plasticity.
What’s going on outside of us?
The SCALE attributes are being positioned as the external orientation. They are tapping into the world of abundant information. That is what our biological sensors are doing and being made for that purpose. We only have five sensors: touch, sight, hearing, smell, and taste. That’s it! Indeed, robots can have hundreds, by the way. This is not a guarantee that they are smarter per se. Let's be honest. We are doing pretty good with these five.
Nature made them relatively advanced. Depending on their uses, one might ask, how are they used to solve our daily problems? Some of the sensors are more developed than humans. Think of a cook or a professional wine taster. A conductor needs his ears differently from what most of us do and hears things in the music that the average person doesn’t hear. Not all human beings need sensors all the time to stay alive. We domesticized our lives by living in shelters and having access to groceries and water that comes out of a tap (at least in most cases). If we look around us, we see many species with a few dominant sensors for them to survive. Examples are an eagle who sees about ten times sharper than we do or a dragonfly with a whopping 30000 ‘eyes’, a dog that can hear and smell better, and a snake that ‘smells’ temperature as well as food. You get the point here.
Abundance?
Tapping into abundance, therefore, is relative. Our sensors are spotting about 11 million data points at any given moment. We are only aware of 40 of them. This is where filters become helpful. These filters have been developed for survival. We can’t process all these data with the 2 pounds of fatty mass floating around inside our skull. These are our internal algorithms, coded by learning from everybody and things around us all the time. These algorithms are holding us in the space of our preferences. We are sensing things related to our preferences better, faster, and excluding data outside that realm. Not that we are not registering those, we are not aware of them. Probably this ‘overshoot’ of data is stored somewhere and is being tapped into and retrieved during our dreams or when we are using our intuition (we sense something without knowing precisely what this is, but it feels good or bad). If we say ‘tapping unlimitedly’ into abundance,’ then you know this is relative. We can ‘only’ tap into a portion of abundance, what is abundantly available, and that is data (not information, since that is the result of one or more processes). Moreover, we don’t need all the data for achieving our goal(s) or, at a higher level, our purpose or Massive Transformative Purpose (MTP).
The MTP and activities we are developing to determine what data we need and where to get them. Our MTP is our ‘umbrella’ filter and ‘guidance’ for our SCALE sensors.
Staff on Demand as a sensor
We sometimes need specialists or people who can do the job that the company can’t do or doesn’t want to do for specific tasks.
Staff on Demand (SoD) brings new insights into the organization that hires them temporarily or soon; staff maybe robots. Robots that execute specific tasks are extremely good in that narrow task. The human variant comes closer to the analogy of a ‘sensor.’ They bring expertise, experience, and patterns of action that fit in an environment where human communication is key. The contextual information that SoD adds to an organization reflects a broader view of the world related to the problem that has to be solved and thus adds more value to the job that has to be done.
Community (and Crowd) as a sensor
Using communities in the right way makes them probably the most powerful sensor. Providing them with tasks to spot certain things in their environment helps us (the company) to be aware of changes and understand the nature of those changes. This may be contributing to the purpose of the company and its activities. My suggestion is to only use community. The crowd is ‘just’ an unspecified community and, therefore, a redundant sensor. Furthermore, a community is an organized collection of people. In contrast, a crowd is unspecified and consequently difficult to gather meaningful data from, which may contribute to the purpose of an organization. You can tap into a crowd to extract some (trend) data. According to the business model canvas, where customer segment is an important part, does most likely not match with the meaning of crowd.
An example of a community is the OpenExO community. The members are extremely well-positioned to sense changes in their environment and share and feed that into the community’s collective intelligence. This can help the coaches and consultants to guide transformations using current insights, experiences, and examples. If an organization is using this attribute, it must specify what is in the organization's interest. Using them as your ears and eyes is a great asset. An example of a crowd is a collection of individuals hanging out in the streets of a city on a sunny day in spring. Some may have a drink, whereas some are shopping, or some want to be there because they want to be around people. Data that we want to collect for the organization can be challenging to extract since people's intentions in this example are very diverse.
Algorithms
Algorithms are code and software developed to process data and create meaningful information or insights. The key here is to what data are we exposing the algorithms. That can only be a part of the ‘abundant’ world and should be derived from the MTP. Algorithms themselves are not in the external world. They use a (well-defined) set of data and process these data inside the organization. Therefore, it cannot be external. Even the algorithms for matching driver and client, in the case of Uber or Lyft, are running on their corporate servers.‘Sensors’ such as SoD or Community are the data collectors.
Even if the algorithms are running on a platform outside the organization (Leveraged Asset), the company owns the data and thus can be positioned inside the organization.
Algorithms, in this sense, are the filters for the company, like the filters we are using in our brain. It reflects the preferences of the organization related to the MTP. Like our brains, a company’s algorithm can be biased, and the data is not always accurate. Our analog (quantum) brain can deal with that ‘inaccuracy’ because, historically, there is not always a distinct 0 or 1. There is a range of about right or wrong, and we go on. Nothing is perfect in nature, and therefore it is beautiful (Wabi-Sabi, as the Japanese call this). In our digital world, things must be perfect, and if the data doesn't lead to what we perceive as perfect, it is not good enough. Maybe algorithms in the age of quantum computing will shed some new light on that ‘analog capability’ in the world of superpositions. For now, and for the sake of this paper, we’ll keep it with the relative truth of the truth that algorithms tell us what is true or not and go with it. After all, experimentation will help us to refine the hypotheses/assumptions.
The focus is on sensing data. However, data processing (algorithms) is something at another level; even if the algorithms are running on an edge system, some data are processed centrally owned by the organization.
Leveraged assets as sensors
What we are using and don’t own is the essence of this attribute. This can also be conceived as a sensor, specifically because assets are becoming more digital. Being in an ecosystem of platforms managed by companies with the expertise will lead us ‘automatically’ to new areas, which could improve our business. New features, sensing new opportunities. A car that we are leveraging, a room, or a piece of software, can trigger new initiatives for our company. Outside the building is where the answers are for new opportunities. Leveraged assets can help us with that because the owner of that asset has that asset for a reason. One of those reasons may be to improve that asset to further engage with you. Those improvements could teach us to change certain aspects. In nature, we know this as “adaptive radiation.”
Engagement as a sensor
The last ‘sensor’ that helps us to tap into the world outside of us is engagement. As a company, you’re engaging with people to keep them as your customer or advocate. This is a powerful sensor because we can learn from them, e.g., by optimizing our data (and thus our algorithms) and making them part of our company by owning parts of our company other than shares, as we see on the stock market. Instead, we could develop NFTs (Non-Fungible Tokens) and make that available for those who want to be connected to your company. They are the sensors that tell us what is important for them to be engaged. NFTs have the capacity to fulfill that need.
The inner world of the organization and the IDEAS attributes
The organization is ingesting the data that is being collected from the world outside. Then analysis can be done by the departments that were collecting them, to begin with, and aggregated information for management decisions.
If we conceive the SCALE attributes as sensors collecting data, interfaces are needed to process them. This probably makes interfaces the most important internally oriented attribute. Without interfaces, the collection of data doesn’t make much sense.
Interfaces
Interfaces are the connectors between the sensors (SCALE) and the start of the sense-making process inside the organization. Not all data use the same interface. E.g., images are a different type of data than data generated by a health app counting the steps or heartbeats or voice data. Likewise, our eyes transport different signals to the optical center than auditory signals stored in the primary auditory cortex. The dedicated parts in the brain make sense of these signals and what passes the filter (our preferences) so that it can be stored. Interfaces, therefore, are a sort of gatekeeper created by the algorithms of our preferences. If this analogy works for organizations, then algorithms in the SCALE attributes belong somewhere else. Algorithms are not sensors. They ‘work’ with the data that sensors produce, not the data itself.
Organizations collecting data from the external world have to be very clear about the nature of these data and figure out how to clean them before exposing them to the algorithms. The cleaning is an internal process that immediately follows when they pass the interfaces. This mechanism is why data scientists are gaining more popularity in an organization. A nice side effect, they pay you well since the supply is less than the demand. Those algorithms will take over this in the future in just a matter of time. That is an even stronger argument for reconsidering the position of algorithms in the IDEAS ExO attributes.
Dashboards
The function of the dashboards can be seen as the awareness of the data that have been collected. Like our brains are processing (algorithms) the data and presenting that in understandable information. Signals (data) hitting the retina will be translated into images that are being recognized by our visual cortex. Graphs are the meaningful visualizations of data helping us navigate and manage the organization. Dashboards are an organization’s ‘survival kit’ in the fast-changing world.
Experimentation
This feature in nature and thus in our body is responsible for who we are for a big part. That is the function of trial/error and learning. The more we expose ourselves to new situations and figure out how to solve problems, the more we learn, and the richer our toolset for actions will be. So you get more options to choose from.
Organizations experimenting a lot probably have a better competitive advantage than those that hardly have embraced experimentation.
Autonomy
Autonomy is a complicated attribute. Unlike our body, where millions of autonomous systems are working to keep us alive, organizations are managed by people. Some of them have a mindset that matches autonomous behavior, whereas others want to be managed. The increase of developments of DAOs (Distributed Autonomous Organizations) that we are seeing today could be a signal of a trend that may be adopted by existing companies as well. DAOs operating ‘in the field’ close to ending users, picking up their ‘signals’ needed for adjusting existing offers and picking up signals which give rise to the development of new solutions. Because of this feature, this attribute can be conceived as a sensor and, therefore, may fit better in the realm of the SCALE attributes.
Social
Social feels a bit strange as an attribute. Social usually refers to being social with one another, but this is not the main reason for working there in organizations. This attribute is more about sharing information in a fast and concise way. Therefore, SHARING is essential to optimize collaboration, and people are using certain technologies for that purpose. These may be solutions such as Dropbox, iCloud, OneDrive, Google Drive, Clickup, Slack, etc., a choice that must be made collectively. The emphasis is on sharing and creating synergy about the information needed to get the job done. An employee of an organization can be seen as a single cell, similar to a single cell in our body (organization). Cells function because they share specific information with other (clusters of) cells (analog to departments in organizations). This information makes sense within that department but has less meaning for another department. The total of all the sharing identifies a company, not the fact that there is a ‘social component.’ This sharing keeps us healthy, keeps an organization healthy, not the social component.
Additional
Many organizations are using more or less digital platforms. E-mail, storage, office tools, HR digital tools, finances, cloud solutions, APIs, etc., are common. If you want to keep up doing business, a company must be digitized. Digitization is the only way to scale at a massive scale. If a company has ‘high touch’ activities, this organization may reside in the risk zone.
Outsourcing an organization’s digital landscape will save resources. You don’t need to have that many IT specialists. The specialists of the outsourcing company are probably more current with respect to the latest technologies because that is their core business. In contrast, organizations use digital solutions and have agreements on proper SLAs (service level agreements).
Therefore, an additional attribute should be the use of digital platforms because this is a sine qua non for exponential organizations. However, not all companies have their core businesses running on platforms yet, as the figure of IDG.com shows, and adding platforms to the IDEAS attributes could be considered.
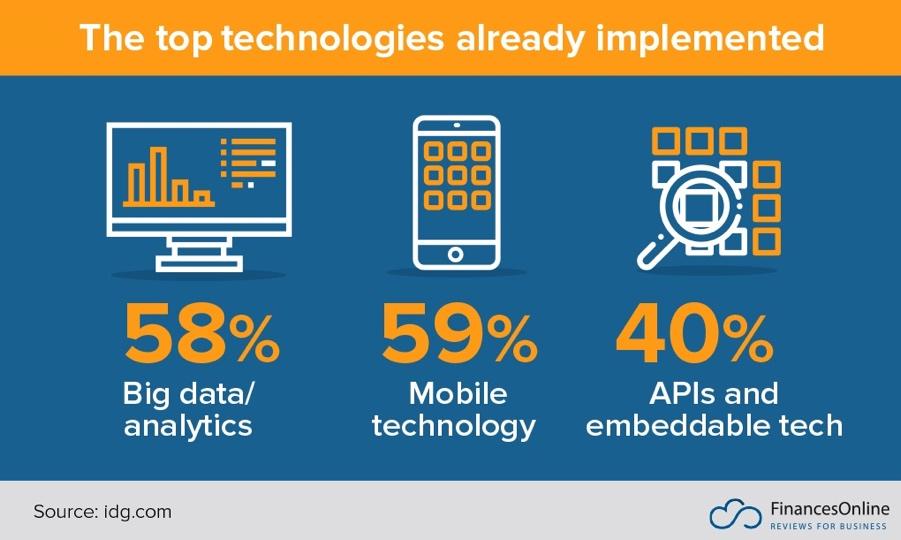
Figure 1: There is room for more platforms
Another attribute that could be considered is the ability to spot and apply converging technologies.
The world is moving quickly to the next version of the Internet: Web 3.0. Companies that are jumping on the bandwagon of Web 3.0 may be better off. An Example that we are witnessing every day is the convergence of Extended Reality. Three dominant technologies responsible for the convergence are Blockchain technology, IoT, and Artificial Intelligence. Robot technology is another example, as well as drones or 4D printing.
I can imagine that the ability to spot and apply could be conceived as a sensor and, therefore, part of the SCALE attributes.
In summary
Using the analogy of how we as human beings (and other mammals) are sensing and processing information may add a perspective that will help us to improve the attributes. After all, organizations are living systems, where everything is connected for a reason. This way of looking led to the consideration of changing the position of autonomy and algorithms and adding two more attributes to the IDEAS and SCALE concept. The new scheme could look like Figure 2.
We don’t need to change the acronyms. For example, if Platforms and Convergence are added, it could be described as IDEAS+ and SCALE+.



ExO Insight Newsletter
Join the newsletter to receive the latest updates in your inbox.








{kind=link}